Get in touch
Artificial intelligence has increasingly been making inroads into companies and their IT projects in recent years. Especially since last year, companies like OpenAI and services like ChatGPT in particular have triggered a lot of hype around the possibilities of LLMs (large language models) and generative AI. Many companies are rightly wondering about how they can best deploy the new possibilities, while taking risk-related topics such as data and privacy protection into account at the same time. These technologies offer innovative solutions to many business challenges, from automating complex tasks to improving interactions with customers.
In this article, we will provide an overview of the transformative potential of generative AI, as well as potential use cases. In addition, we will present an example to show how language models can be used to generate new applications and added value from in-house information and knowledge bases.
Generative artificial intelligence (AI) is a type of artificial intelligence that is capable of generating new content such as texts, images, videos, and music whose quality can hardly be distinguished from content created by humans (or not at all).
One sub-area of generative AI that has made astounding progress, particularly in recent years, involves LLMs – large language models that form the foundation of well-known applications like ChatGPT, Google Bard, and Midjourney. Originally developed to generate text-based content, LLMs have now become capable of handling a variety of tasks in a wide range of areas:
Technically speaking, a large language model is a complex neural network that is trained on a huge amount of data (books, articles, websites, and the like) to understand meanings, concepts, and interconnections in natural language. This trained knowledge is coded in the form of parameters, which the model uses to generate answers to user queries that have a certain probability of being correct. The “size” of a language model refers to the number of parameters, or elements, in the neural network and thus its fundamental ability to learn complex patterns. The architecture of OpenAI’s GPT-4, for instance, uses around 1.76 trillion parameters. The more parameters a model has, the more computing power is needed. In addition to the number of parameters and the training data, there are many other properties that can be used to assess a model. We will examine a few of them in more detail further below.
Queries are submitted to the model in the form of prompts – a question, the beginning of a sentence, or additional context that serves as the initial text for which the model generates the answer. It is important to note, however, that language models can also deliver inaccurate or imprecise results, which are called “hallucinations”. One reason why hallucinations can occur is that the model simply does not know the answer to a question. ChatGPT 3.5 was trained on data collected up to January 2022, for example, which is why the chatbot cannot answer questions that go beyond this cutoff date. Another reason, already mentioned above, is that the answers generated by an LLM are based on probabilities (and, of course, on the quality of the underlying training data). This can result in the generation of factually wrong or even fictitious content. However, hallucinations can be desirable in the context of creative answers, since the model is prompted to produce novel ideas and concepts that are not actually present in the training data.
Important criteria for large language models include:
Model size (number of parameters): This is a key characteristic of LLMs. As mentioned above, the number of parameters determines the capacity of the model for understanding complex patterns and interconnections. Models with more parameters are typically more powerful, but also need more computing capacity for training and use. What’s more, smaller models that are trained for specific tasks or with specific domain knowledge may return better results.
Context window size: The context window size refers to the number of words or partial words (called “tokens”) that the model can process in a single query. A larger context window size enables the model to take longer text passages into account and improves both the understanding of interconnections and the coherence of answers. GTP-4, for instance, has a context window size of 32,768 tokens.
Efficiency – especially RAM requirements: Larger models need more memory in order to save and process the model parameters. This can affect the deployment and scalability of a model.
Data quality and diversity: The type and spectrum of the training data determine how well the model is capable of understanding different language styles, topics, and contexts.
Training method and intended use: A number of models are trained and fine-tuned for specific intended uses. For example, there are models that are optimized for image generation, voice recognition, question-and-answer scenarios, and so on.
The main differences between closed-source and open-source language models are their accessibility and potential uses. Closed-source language models are typically developed by large tech companies or research institutions and usually operated commercially, which means users must pay license fees, subscription fees, or the costs of API accesses. The source code is not made public in these models, so users and developers cannot see how the model is structured, which algorithms are used internally, or how the model was trained. Accordingly, options to customize the models for proprietary applications are often limited. Examples of well-known closed-source language models include ChatGPT and GPT-4 from OpenAI, Google Bard, and Anthropic’s Claude.
In contrast, open-source models are often available freely and permit developers to customize or enhance the model in order to implement their own specific solutions based on the new foundation. They are usually free of charge and often have license-friendly terms that allow widespread use. It is important to note, however, that operating a language model can incur significant costs for the IT infrastructure (depending on the size of the model and the number of accesses per day), regardless of whether it is run on premise or uses cloud services. Well-known examples of (commercially usable) open-source models include Meta’s LLama 2, Falcon from TII UAE, MosaicML MPT, and Mistral7B from Mistral AI.
It is impossible to say which model is the “best” in general, because that depends on the specific use case at hand. Based on factors such as the suitability, performance, and adaptability of the model; operating and training costs; the desired level of data security; and other factors, potential users must decide whether they want to run a proprietary model or turn to a commercial solution.
How can existing language models be customized for a company’s in-house applications? In the next section, let’s examine the different training options for LLMs.
How can language models be trained?
Retrieval-augmented generation (RAG) describes an architecture that combines an information retrieval model with a large language model. When a query is submitted, the retrieval model searches its database for potentially relevant information – which can stem from text documents, websites, or other data sources – and then passes this information on to the language model together with the query. As a result, the model can utilize the additional information in the framework of in-context learning to better understand the query and generate a more precise answer.
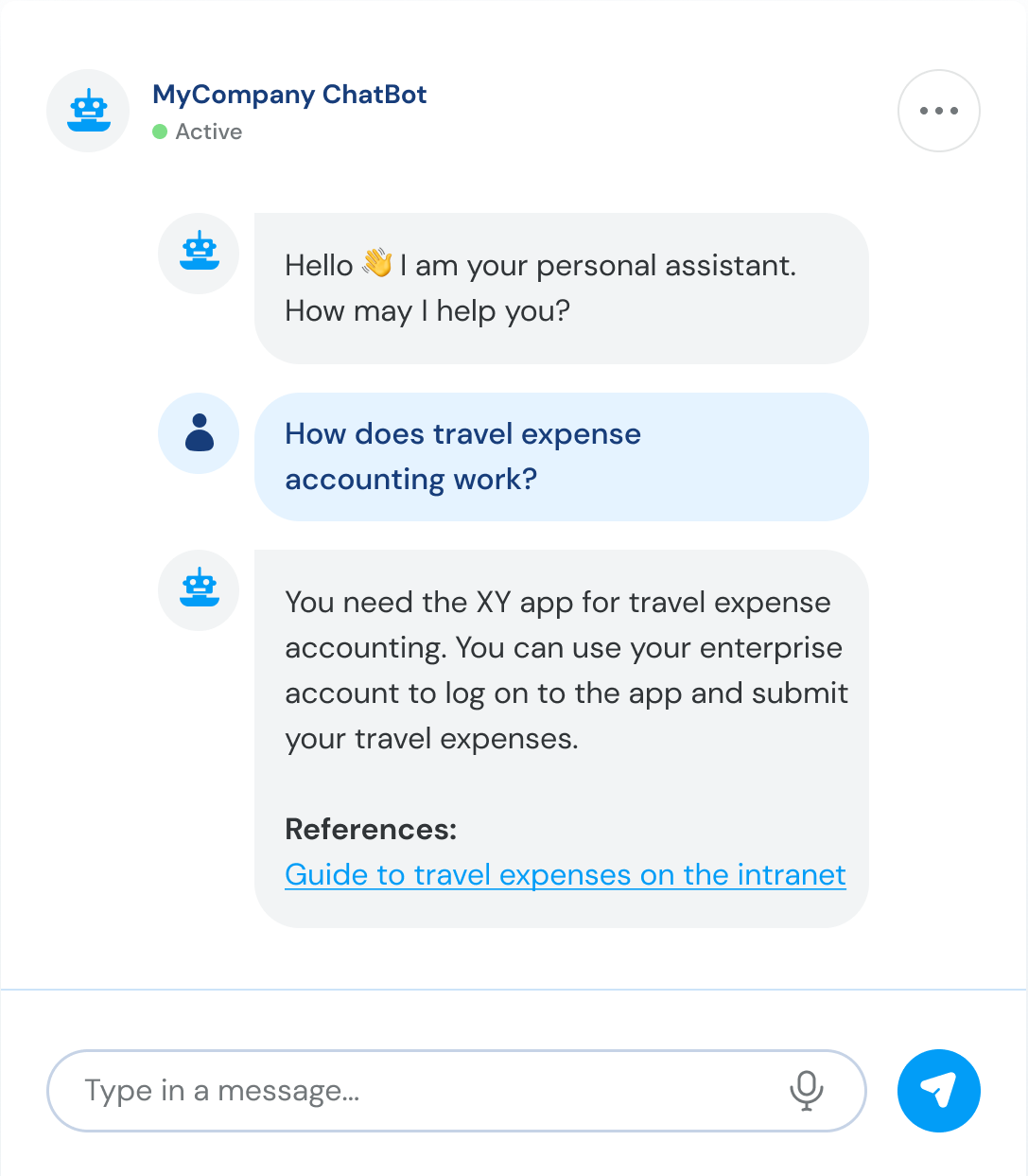
Let’s examine a specific use case: a chatbot that enables free-text search of a knowledge base such as Confluence. How does the retrieval model find the right information for a query in this case?
Several advance steps are needed. First, the underlying data is exported from Confluence (as HTML documents, for example). Each of these documents is then split into chunks (smaller parts like sentences or words), which in turn are converted to embeddings (vector representations) that are better suited to processing by machine learning algorithms. These vectors are designed to map the meanings and relationships between different words and phrases in such a way that words with similar meanings will (ideally) be close together in the vector space. In conclusion, the generated vectors and a reference to the corresponding documents are saved in a vector database, such as ChromaDB or Pinecone, for fast access. When a question is then asked of the chatbot, that question is then split into its individual components – like the documents previously – and compared with the entries in the vector database. The content that is most similar to the question, and therefore the most relevant, is returned by the database and fed into the language model as context. The answer generated by the language model is then displayed as the result in the chatbot.

The integration of large language models in enterprise applications marks a watershed in the digital transformation. These models not only enable companies to optimize their processes and improve their communications, but also open up new horizons for personalized services, precise analytics, and efficient decision-making. Their versatility makes them a useful tool for companies that aspire to create innovative solutions, to become and remain successful in a constantly changing and increasingly data-driven business world.



